


Transformers have revolutionized the field of natural language processing (NLP) since their introduction in 2017. Unlike Recurrent Neural Networks (RNNs), Transformers can process sequential data out of order, making them more efficient and faster. This blog post aims to demystify the complex architecture of Transformers and explain their workings in a simplified manner.
In the rapidly evolving world of Natural Language Processing (NLP), one model has emerged as a game-changer: the Transformer. Introduced in 2017, this deep learning model has swiftly become a cornerstone of modern NLP, powering applications from machine translation to text summarization. Unlike its predecessors, the Transformer has the unique ability to process sequential data in a non-sequential manner, leading to significant improvements in efficiency and speed. This blog post aims to unravel the intricacies of the Transformer model, breaking down its complex architecture into understandable segments, and shedding light on the inner workings of this powerful tool in the realm of deep learning.
Understanding Transformers
Transformers, first introduced in the seminal paper “Attention is All You Need” by Vaswani et al. (2017), have revolutionized the field of deep learning and Natural Language Processing (NLP). These models are unique in their use of a mechanism known as self-attention, which allows them to understand the context and relevance of words in a sentence.
The self-attention mechanism is a departure from traditional models that rely on sequence-dependent structures, such as Recurrent Neural Networks (RNNs) or Long Short-Term Memory (LSTM) networks. Instead of processing words in a sentence sequentially, Transformers can process all words in the sentence simultaneously, making them highly parallelizable and efficient.
The self-attention mechanism works by creating a weighted representation of the input sentence, where the weight assigned to each word depends on its relevance to the other words in the sentence. For instance, consider the sentence: “The cat, which already had its dinner, chased the mouse.” When encoding the word “chased”, a Transformer model would assign higher attention scores to “cat” and “mouse”, as these words are most relevant to understanding the action of “chasing”. This ability to capture the interdependencies between words in a sentence is what makes Transformers particularly powerful for NLP tasks.
This concept of self-attention can be further illustrated with the help of the following equation, as described in the original paper.

In this equation, the attention score (A) for a given word is calculated as the dot product of the query vector (Q) and key vector (K), divided by the square root of the dimension of the key vector (d_k). This score is then passed through a softmax function to ensure that all scores sum to 1. The final output (Z) is a weighted sum of the value vectors (V), where the weights are the softmax scores.
This self-attention mechanism is at the heart of the Transformer’s ability to understand the context and relevance of words in a sentence, making it a powerful tool for a wide range of NLP tasks, from machine translation to text summarization.
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., … & Polosukhin, I. (2017). Attention is all you need. In Advances in neural information processing systems (pp. 5998-6008).
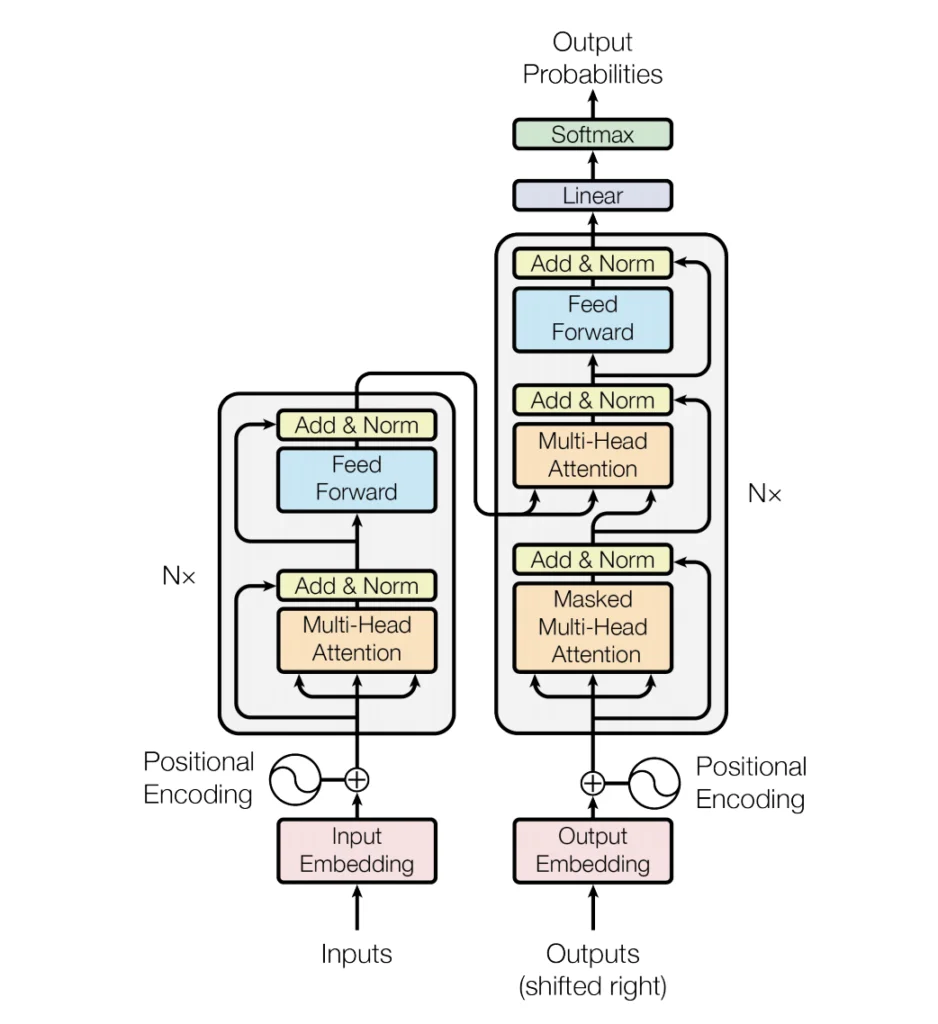
The Encoder-Decoder Architecture
The Transformer model consists of two main components: the Encoder and the Decoder. The Encoder maps an input sequence into an abstract continuous representation that holds all the learned information of that input. The Decoder then takes that continuous representation and generates a single output while also being fed the previous output.
Diving Deep into the Encoder Architecture
Each Encoder consists of two sub-layers: the Self-Attention Layer and the Feed Forward Neural Network Layer. The Self-Attention Layer enables the model to learn the correlation between the current words and the previous part of the sentence. The Feed Forward Neural Network Layer processes the outputs generated by the Self-Attention Layer.
The Concept of Multi-Headed Attention
The researchers introduced the concept of Multi-Headed Attention to capture various different aspects of the input. This mechanism computes multiple attention weighted sums instead of a single attention pass over the values, hence the name “Multi-Head” Attention.
Positional Encodings
Unlike recurrent neural networks, the multi-head attention network cannot naturally make use of the position of the words in the input sequence. To solve this problem, positional encodings are used to explicitly encode the relative/absolute positions of the inputs as vectors and are then added to the input embeddings.
The Decoder
The Decoder architecture is similar to that of an Encoder, with an extra “masked multi-head attention” layer which helps the Decoder put more attention on the relevant places in the input sequence.
The Final Layers
After the Decoder layer processes the outputs as vectors, the output goes through a final linear layer, acting as a classifier. This output is then fed to a Softmax Layer to generate probability values ranging between 0 to 1.
Conclusion
Transformers have brought a significant shift in the field of NLP, making tasks like translation, summarization, and sentiment analysis more efficient and accurate. Understanding their architecture and working can provide a solid foundation for anyone interested in diving deep into the world of NLP.